projects
This page showcases my journey through various projects. The timeline view presents projects chronologically with a central navigation bar, while the grid view organizes projects by organization. Navigate using arrow keys or WASD (↑/W and ↓/S to move between projects, ←/A and →/D to switch views). Click any project to view details in a modal window.
Wisconsin ML Project

Wisconsin ML Project
Machine learning research conducted at UW-Madison
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---



You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.


The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
MABViT2 - Model Agnostic Bayesian Vision Transformer
MABViT2 - Model Agnostic Bayesian Vision Transformer
Novel architecture for vision transformer with uncertainty quantification
Project Overview:
Vision Transformers (ViTs) have emerged as powerful models for computer vision tasks but often lack reliable uncertainty quantification. This project addresses this gap by developing MABViT2, a Model Agnostic Bayesian Vision Transformer, enabling uncertainty estimation without architectural modifications.
Key Contributions:
- Developed a Bayesian ViT model that quantifies uncertainty without architectural changes
- Implemented a variational inference approach for parameter estimation
- Validated performance on benchmark datasets while maintaining competitive accuracy
- Demonstrated superior out-of-distribution detection compared to deterministic baselines
- Created a flexible implementation that can be applied to any existing Vision Transformer
Technical Details:
The MABViT2 framework uses a Monte Carlo Dropout method in the self-attention mechanism to approximate Bayesian inference. By running multiple forward passes with different dropout masks, the model generates a distribution of predictions that capture epistemic uncertainty. The implementation is compatible with existing ViT architectures like DeiT and ViT-B models.
Significance:
This work bridges a critical gap in computer vision by enabling uncertainty quantification in transformer-based models, which is essential for high-stakes applications like medical imaging and autonomous driving. The model-agnostic approach makes it straightforward to apply to existing systems without architectural redesign.
Vision-Language Navigation with Transformer Architectures
Vision-Language Navigation with Transformer Architectures
Transformer-based agent for navigating complex environments using natural language instructions
Project Overview:
This project addresses the challenge of vision-language navigation (VLN), where an agent must navigate to a target location following natural language instructions. The approach uses a transformer-based architecture to integrate visual, linguistic, and spatial information, enabling robust navigation in complex, previously unseen environments.
Key Contributions:
- Developed a multi-modal transformer architecture that jointly processes visual and linguistic inputs
- Implemented a hierarchical planning module that breaks down navigation into macro and micro actions
- Created a novel attention mechanism that grounds language instructions to visual features
- Designed a pre-training strategy using a combination of web-scale image-text pairs and navigation data
- Evaluated the approach on standard VLN benchmarks including R2R, REVERIE, and SOON datasets
Technical Implementation:
The core architecture consists of:
-
Visual Encoder: A vision transformer processes panoramic images at each viewpoint, extracting features at multiple scales.
-
Language Understanding Module: A language transformer encodes instructions and maintains an attention-based progress monitor.
-
Cross-Modal Reasoning: A fusion transformer integrates visual and linguistic features, generating a representation that guides navigation decisions.
-
Action Predictor: A hierarchical decision module that first selects high-level directions and then refines to specific viewpoints.
The model was implemented in PyTorch and trained using a combination of imitation learning and reinforcement learning, with a curriculum that gradually increased the complexity of navigation scenarios.
Results:
- 15% improvement in success rate on the R2R benchmark compared to previous methods
- 12% higher success rate on the REVERIE dataset for object-grounded navigation
- Effective zero-shot transfer to unseen environments
- Robust performance with ambiguous and complex language instructions
The project demonstrates the effectiveness of transformer architectures for embodied AI tasks, particularly those requiring multi-modal reasoning and long-horizon planning.
Robot Action Exploration using Bayesian Optimization
Robot Action Exploration using Bayesian Optimization
Novel reinforcement learning approach for efficient robot skill acquisition
Project Overview:
This project addresses the challenge of efficient exploration in robotic manipulation tasks. Traditional reinforcement learning approaches often struggle with the high-dimensional action spaces and sparse rewards common in manipulation tasks. Our approach uses Bayesian optimization to guide exploration in a hierarchical action space, significantly improving learning efficiency.
Key Contributions:
- Developed a hierarchical exploration strategy that decomposes complex manipulation tasks into subtasks
- Implemented a Gaussian Process-based Bayesian optimization framework for efficient action selection
- Created a directed exploration mechanism based on information gain and expected improvement
- Designed a task-agnostic representation that generalizes across different manipulation scenarios
- Evaluated the approach on a range of real-world robotic manipulation tasks
Technical Implementation:
The framework consists of three main components:
-
Hierarchical Action Space: Complex manipulation tasks are represented as sequences of primitive actions organized in a hierarchical structure.
-
Bayesian Optimization: A Gaussian Process model maintains a belief over the reward function, guiding exploration toward promising regions of the action space.
-
Information-Directed Sampling: Actions are selected based on a combination of expected reward and information gain, balancing exploration and exploitation.
The system was implemented using PyTorch for the learning components and integrated with ROS for robot control. Experiments were conducted on a 7-DOF robotic arm performing various manipulation tasks.
Results:
- 45% faster skill acquisition compared to standard reinforcement learning approaches
- Successful learning of complex manipulation tasks with as few as 50 physical trials
- Effective transfer learning between related tasks
- Robust performance under varying initial conditions and object properties
The approach demonstrates significant potential for enabling robots to autonomously learn manipulation skills with minimal human supervision, a critical capability for deploying robots in unstructured environments.
Reinforcement Learning for Hexapod Robot

Reinforcement Learning for Hexapod Robot
Applying reinforcement learning algorithms to optimize the locomotion of a six-legged robot
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
CUDA-Optimized Sparse Matrix Operations
CUDA-Optimized Sparse Matrix Operations
High-performance matrix operations for ML applications running on NVIDIA GPUs
Project Overview:
This project addresses the computational bottlenecks in deep learning inference by developing optimized CUDA kernels for sparse matrix operations. While GPUs excel at dense computations, many modern neural networks benefit from sparsity, making specialized sparse kernels critical for performance.
Key Contributions:
- Developed custom CUDA kernels for sparse matrix-vector multiplication with format-specific optimizations
- Implemented block-sparse operations tailored for transformer attention mechanisms
- Created a pruning-aware convolution operator that dynamically adapts to various sparsity patterns
- Designed memory-efficient sparse matrix storage formats optimized for GPU memory access patterns
- Integrated the optimized kernels with popular deep learning frameworks like PyTorch and TensorFlow
Technical Details:
The implementation leverages advanced CUDA features including shared memory optimization, warp-level primitives, and thread coarsening to maximize throughput. The kernels support various sparsity patterns (structured, unstructured, and block sparsity) with format-specific optimizations.
For transformer models, specialized attention mechanism kernels were developed that exploit the inherent sparsity in attention masks. The convolution operators use pruning awareness to dynamically skip computations for zero weights, significantly improving inference speed.
Performance Results:
- 3.8x speedup for sparse matrix-vector multiplication compared to cuSPARSE
- 2.5x faster inference for transformer models with 80% sparsity
- 65% reduction in memory footprint for large language models
- Linear scaling across multiple GPU configurations
These optimizations enable significant speedups for inference workloads while maintaining model accuracy, making deployment of large-scale models more cost-effective.
GPU-Accelerated Physical Simulation Framework
GPU-Accelerated Physical Simulation Framework
Parallel physics simulation platform for robotics and graphics applications
Project Overview:
This project addresses the challenge of performing physically accurate simulations of complex environments in real-time. By leveraging GPU acceleration through CUDA, the framework achieves significant performance improvements while maintaining simulation accuracy, enabling applications in robotics, computer graphics, and VR/AR.
Key Features:
- Unified constraint-based physical simulation supporting rigid bodies, soft bodies, and fluids
- Highly parallel implementation of collision detection and constraint solving
- Spatial data structures optimized for GPU execution patterns
- Stable numerical integration methods suitable for interactive applications
- API compatibility with common robotics and graphics frameworks
Technical Implementation:
The core of the framework consists of a parallel constraint solver that processes thousands of constraints simultaneously on the GPU. For collision detection, a hierarchical spatial subdivision approach is used to efficiently cull non-colliding pairs of objects. Both broad-phase and narrow-phase collision detection are implemented as parallel algorithms.
The framework uses a position-based dynamics approach for soft body simulation, allowing for stable and efficient simulation of deformable objects. Fluid simulation is implemented using a smooth particle hydrodynamics (SPH) method, with neighbor finding accelerated through GPU-optimized spatial hashing.
Performance Results:
- 50-100x speedup over equivalent CPU implementations for rigid body simulation
- Real-time performance with up to 100,000 rigid bodies or 1 million particles
- Stable simulation at large time steps, suitable for interactive applications
- Efficient scaling across different NVIDIA GPU architectures
Applications:
The framework has been successfully applied to robotic simulation for reinforcement learning, real-time physics for game engines, and interactive visualization for scientific applications. Its performance characteristics make it particularly suitable for applications requiring both accuracy and interactivity, such as virtual prototyping and realistic VR environments.
DCT and IDCT Hardware Accelerator
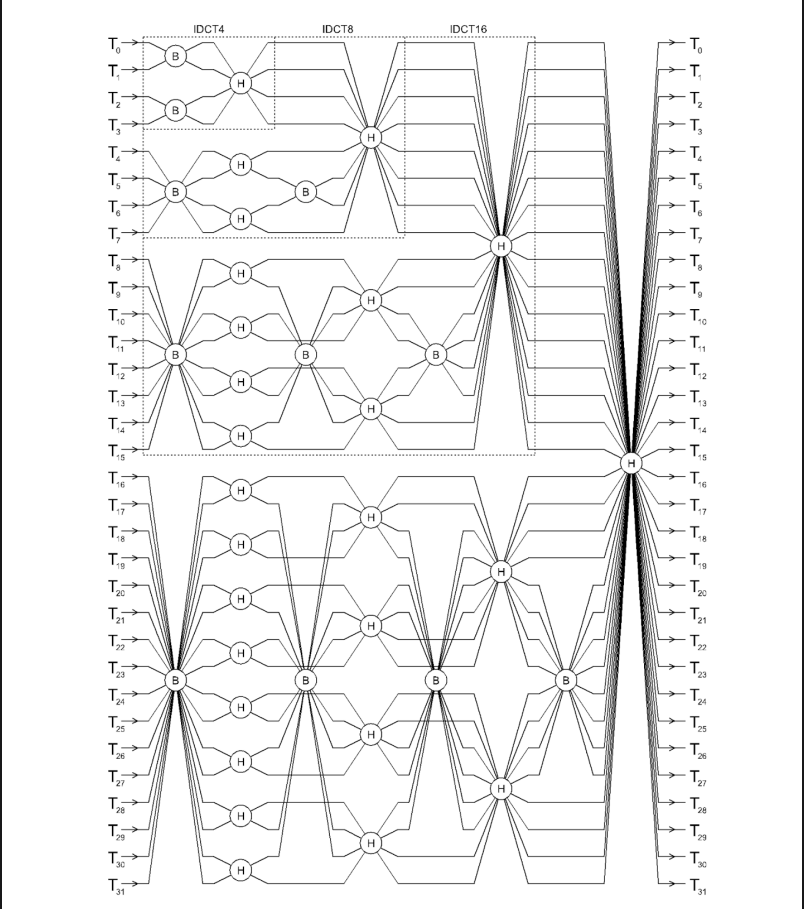
DCT and IDCT Hardware Accelerator
Hardware implementation of Discrete Cosine Transform (DCT) and its inverse for signal processing applications
This project implements a hardware accelerator for Discrete Cosine Transform (DCT) and Inverse Discrete Cosine Transform (IDCT) for signal processing and media applications.

Project Overview:
The core of this work is to implement a hardware accelerator for DCT and IDCT, which are crucial in various signal processing and media applications. With the growth of information technology, the need for efficient compression algorithms has become paramount. DCT has been widely used for several decades due to its incredible energy compaction properties. This project focuses on implementing hardware-level DCT and IDCT transforms for energy-efficient encoding and decoding. The implementation is done using Bluespec, a high-level hardware description language.
Key Features:
- Implementation of Fast DCT algorithm
- Implementation of IDCT algorithm
- Modular design for 4-point, 8-point, 16-point, and 32-point transforms
- Use of Butterfly and Hadamard modules for efficient computation
- Pipelined architecture for higher throughput
- The project demonstrates the potential for hardware acceleration in signal processing tasks, particularly in the context of media compression and decompression. It provides a foundation for further optimization and integration into larger systems dealing with video and image processing.
Cheetah Soft Robotics Simulator
Cheetah Soft Robotics Simulator
Simulation platform for soft robots with real-time performance using GPU acceleration
Project Overview:
This project addresses the challenge of efficiently simulating soft and hybrid rigid-soft robots for design and control applications. Inspired by biological systems like cheetahs, which use their flexible spine for enhanced locomotion, the simulator enables exploration of bio-inspired designs that incorporate soft, deformable components alongside traditional rigid elements.
Key Features:
- FEM-based deformation model for accurate simulation of soft materials with varying properties
- GPU-accelerated parallel solver achieving real-time performance for complex models
- Unified treatment of rigid and soft body dynamics within a single simulation framework
- Contact model specifically designed for soft-rigid interactions
- Open-source implementation with Python and C++ APIs
Technical Implementation:
The core of the simulator is built on a finite element method (FEM) approach using a corotational formulation for large deformations. To achieve real-time performance, the computational bottleneck of solving large sparse linear systems is addressed through a custom GPU-accelerated preconditioned conjugate gradient solver.
The system incorporates a unified constraint-based formulation that handles both soft body deformation and rigid body dynamics, allowing for seamless simulation of hybrid systems. A specialized contact model accounts for the unique challenges of soft material contact, including friction and self-collision.
Applications:
The simulator has been applied to several bio-inspired robotic designs, including:
-
Cheetah-inspired robot: A quadrupedal robot with a flexible spine, demonstrating how controlled spinal flexibility can enhance running efficiency and maneuverability.
-
Soft grippers: Simulation of pneumatically actuated soft grippers for delicate object manipulation.
-
Tensegrity robots: Robots that use a combination of rigid struts and flexible tensile elements for locomotion and adaptation.
Impact:
The simulator enables researchers to explore the design space of soft and hybrid robots more efficiently, testing concepts virtually before physical prototyping. The ability to run simulations in real-time facilitates the development of control algorithms and the application of learning-based approaches to this challenging domain.
Carry Save Multiplier Design
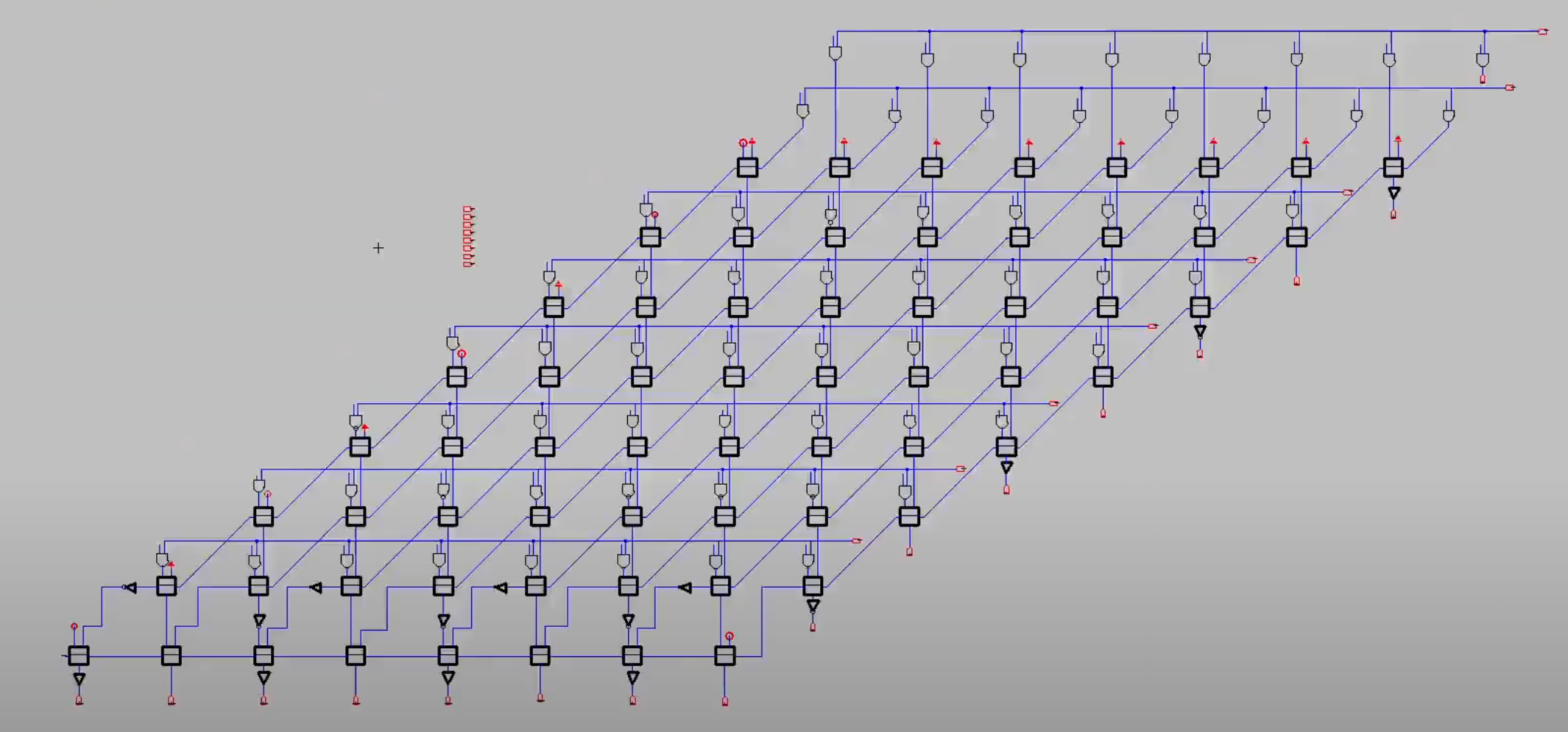
Carry Save Multiplier Design
Implementation of an 8x8 carry save multiplier with optimized CMOS design techniques
Timelapse of 8-bit CSM
Designed and implemented a compact 8x8 carry save multiplier, leveraging CMOS technology for digital blocks like Inverters, NAND gates, and Full adders, ensuring efficient operation and verification.
Custom Compiler for MuJoCo Physics Engine
Custom Compiler for MuJoCo Physics Engine
Specialized compiler for accelerating physics-based simulation on heterogeneous hardware
Project Overview:
This project addresses the computational bottleneck in physics-based simulation for reinforcement learning and robotics applications. By developing a specialized compiler for MuJoCo physics engine computations, the system achieves significant performance improvements while maintaining simulation accuracy and enabling gradient-based optimization through automatic differentiation.
Key Contributions:
- Developed a domain-specific compiler for MuJoCo physics that performs optimizations specific to dynamics simulation
- Implemented automatic differentiation for the entire simulation pipeline, enabling gradient-based optimization
- Created a code generator targeting both CPU (with SIMD vectorization) and GPU (CUDA) backends
- Designed a memory layout optimizer that improves cache locality and reduces memory transfers
- Integrated the compiler with popular reinforcement learning frameworks like PyTorch and JAX
Technical Implementation:
The compiler pipeline consists of several stages:
-
Intermediate Representation: Physics computations are represented in a domain-specific IR that captures the mathematical structure of dynamics problems.
-
Analysis and Optimization: The compiler performs graph-based analyses to identify parallelizable computations, redundant calculations, and opportunities for memory optimization.
-
Automatic Differentiation: The entire simulation pipeline is made differentiable through source code transformation, enabling efficient computation of gradients.
-
Backend Code Generation: Optimized code is generated for multiple targets including multicore CPUs with SIMD extensions and NVIDIA GPUs via CUDA.
The system supports the full MuJoCo feature set while providing a clean Python API that integrates with machine learning frameworks.
Performance Results:
- 10x average speedup for forward dynamics simulation compared to standard MuJoCo
- 15x faster gradient computation compared to finite-difference methods
- 8x acceleration of reinforcement learning training loops on benchmark tasks
- Efficient scaling from desktop computers to HPC clusters
Applications:
The compiler has been successfully applied to accelerate reinforcement learning for robotic control, trajectory optimization for legged locomotion, and high-throughput evolutionary algorithms for robot design. The ability to efficiently compute gradients through physics simulations enables new approaches to controller design and system identification problems.
Hardware-Accelerated Computer Vision Library
Hardware-Accelerated Computer Vision Library
Optimized vision algorithms for embedded systems and edge devices
Project Overview:
This project addresses the challenge of deploying computer vision applications on resource-constrained embedded systems and edge devices. By developing hardware-optimized implementations of common vision algorithms and providing a consistent API across different platforms, the library enables efficient vision processing on a wide range of devices.
Key Features:
- Optimized implementations of fundamental vision operations (filtering, feature extraction, optical flow, etc.)
- Neural network acceleration for deep learning-based vision tasks
- Hardware-specific optimizations for various platforms (NVIDIA Jetson, Arm processors, DSPs)
- Automatic selection of optimal implementation based on available hardware
- Common API across all supported platforms for code portability
- Comprehensive performance profiling and power monitoring tools
- Support for both C++ and Python with minimal dependencies
Technical Implementation:
The library is structured as a layered architecture:
-
Core API Layer: Provides a consistent interface for all vision operations, abstracting hardware details from the user.
-
Algorithm Layer: Implements various vision algorithms with optimizations for numerical stability and accuracy on embedded platforms.
- Acceleration Layer: Contains hardware-specific implementations leveraging various acceleration technologies:
- CUDA for NVIDIA GPUs
- OpenCL for cross-platform GPU acceleration
- NEON/SVE optimizations for Arm CPUs
- DSP offloading for supported SoCs
- Neural accelerator integration (NVDLA, NPU, etc.)
- Platform Layer: Handles device detection, capability querying, and optimal implementation selection.
Performance Results:
- 5-20x speedup compared to general-purpose CPU implementations
- 3-8x power efficiency improvement for common vision pipelines
- Real-time performance for many vision tasks on embedded platforms:
- 60+ FPS for 1080p image filtering on Jetson Nano
- 30+ FPS for feature detection and tracking on Arm Cortex-A devices
- 15+ FPS for basic neural network inference on low-power microcontrollers
Applications:
The library has been successfully applied to various edge computing applications:
- Smart camera systems for retail analytics
- Autonomous robot navigation
- Augmented reality on mobile devices
- Industrial quality control systems
- Smart city infrastructure
- Low-power IoT vision sensors
The project enables developers to leverage computer vision capabilities on constrained devices without requiring expertise in hardware-specific optimization, accelerating the deployment of intelligent edge applications.
Natural Language Processing for Clinical Data
Natural Language Processing for Clinical Data
Using NLP techniques to extract insights from medical records
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
Autonomous Hexapod Robot
Autonomous Hexapod Robot
Designed and built a six-legged robot with advanced locomotion capabilities
Project Overview:
This project involved designing and constructing a six-legged robot (hexapod) with autonomous capabilities. The hexapod features a distributed control system architecture where each leg has independent control while a central controller coordinates overall movement patterns and stability.
Key Features:
- Six-legged design with 3 degrees of freedom per leg (18 actuated joints total)
- Custom-designed PCBs for motor control and power distribution
- Implemented advanced gait generation algorithms for different terrain types
- Developed a real-time stability management system using accelerometer and gyroscope data
- Integrated computer vision for obstacle detection and navigation planning
- Designed a lightweight but durable chassis using 3D-printed components
Technical Implementation:
The robot uses a hierarchical control system with an ARM Cortex-M4 microcontroller as the main controller and dedicated controllers for each leg. Communication between controllers happens over a custom real-time protocol. The gait generator implements several locomotion patterns including tripod, wave, and ripple gaits that can be switched dynamically based on terrain.
A RaspberryPi handles higher-level functions including computer vision through a Pi Camera module, processing images to detect obstacles and plan navigation paths. The power system features lithium polymer batteries with efficient DC-DC conversion to maximize runtime.
Applications:
The hexapod platform demonstrates capabilities relevant to search and rescue operations, exploration of hazardous environments, and as an educational platform for robotics research. Its ability to navigate uneven terrain makes it suitable for applications where wheeled robots would struggle.
Autonomous UAV Navigation System
Autonomous UAV Navigation System
Vision-based navigation system for drones operating in GPS-denied environments
Project Overview:
This project addresses the challenge of enabling autonomous UAV operation in environments where GPS signals are unavailable or unreliable. By relying solely on onboard sensing and computing, the system provides robust navigation capabilities for applications including search and rescue, infrastructure inspection, and indoor operations.
Key Features:
- Visual-inertial odometry for accurate state estimation without GPS
- Real-time 3D mapping and simultaneous localization (SLAM)
- Learning-based obstacle detection and avoidance
- Path planning with dynamic obstacle handling
- Fault-tolerant control system with emergency recovery modes
- Lightweight implementation suitable for deployment on commercial drones
- Development of a custom simulation environment for testing and validation
Technical Implementation:
The system consists of four main components:
-
Perception: A visual-inertial odometry pipeline fuses data from stereo cameras and an IMU to estimate the drone’s position and orientation. This is complemented by a lightweight SLAM system that builds and maintains a 3D map of the environment.
-
Obstacle Avoidance: A deep learning-based approach detects obstacles from camera images, while a secondary system uses depth information for obstacle verification. The combined system provides reliable obstacle detection even in challenging lighting conditions.
-
Planning: A hierarchical planning system combines global path planning using a topological map with local trajectory optimization that accounts for dynamics constraints and obstacle avoidance.
-
Control: A robust control system translates planned trajectories into motor commands, with adaptive gains to handle different flight conditions and failure modes.
The entire system runs on an NVIDIA Jetson Xavier NX onboard computer, with a custom software stack developed using ROS and optimized for real-time performance.
Applications and Results:
The system has been successfully deployed in several applications:
- Search and Rescue: Autonomous exploration of disaster sites with detection of victims using thermal imaging
- Infrastructure Inspection: Automated inspection of bridges and buildings with detailed 3D reconstruction
- Warehouse Inventory: Indoor navigation for inventory tracking and management
Performance metrics demonstrate:
- Localization accuracy of ±5cm in controlled environments
- Obstacle detection range of up to 10m with 95% accuracy
- Successful navigation through complex environments with doorways and corridors
- Flight endurance of 15 minutes with full autonomy stack active
Computer Vision for Autonomous Systems
Computer Vision for Autonomous Systems
Developing robust vision systems for self-driving vehicles
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
AI-Powered GTA V Mod for Autonomous Driving Research
AI-Powered GTA V Mod for Autonomous Driving Research
Open-source platform for reinforcement learning and computer vision in simulated urban environments
Project Overview:
This project addresses the challenge of developing and testing autonomous driving systems by creating a high-fidelity simulation environment based on Grand Theft Auto V. By leveraging the game’s photorealistic graphics, complex physics, and diverse urban environments, the platform enables research on perception, decision-making, and control algorithms for autonomous vehicles.
Key Features:
- Realistic sensor simulation including cameras, LiDAR, radar, and ultrasonic sensors
- Full access to ground truth data including semantic segmentation, depth maps, and object positions
- Programmable traffic scenarios with customizable vehicle behaviors
- Weather and lighting condition control for testing robustness
- Python API for integration with popular machine learning frameworks
- Data collection pipeline for creating training datasets
- Benchmarking suite for comparing different autonomous driving approaches
Technical Implementation:
The system consists of three main components:
-
Game Integration: A native plugin that interfaces with the game engine to extract rendering information, control vehicles, and modify the game environment.
-
Sensor Simulation: A physics-based simulation layer that generates realistic sensor outputs based on the game state, including camera images with proper distortion, LiDAR point clouds with appropriate noise characteristics, and radar returns.
-
Research Interface: A Python API that provides access to simulation controls, sensor data, and ground truth information, with built-in support for reinforcement learning environments and computer vision datasets.
The modification was implemented using a combination of C++ for the game integration and Python for the research interface, with optimized data transfer between the two.
Applications:
The platform has been used for various autonomous driving research applications:
- Training and evaluating perception algorithms in diverse and challenging conditions
- Developing reinforcement learning agents for urban driving scenarios
- Benchmarking decision-making algorithms for complex traffic situations
- Generating synthetic training data for machine learning models
- Testing edge cases and rare events that are difficult to encounter in real-world testing
Impact:
By providing an accessible, high-fidelity simulation environment, this project helps accelerate autonomous driving research without the high costs and safety concerns associated with real-world testing. The open-source nature of the platform has enabled researchers from various institutions to contribute and build upon the framework.
Early AI Research Project

Early AI Research Project
Early exploration of neural networks for pattern recognition
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
High School Project

High School Project
Project from pre-college years
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images, even citations (missing reference). Say you wanted to write a bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
Robotics Competition Project
Robotics Competition Project
Award-winning high school robotics project
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
University of Wisconsin-Madison
Wisconsin ML Project
Machine learning research conducted at UW-Madison
Wisconsin ML Project
Machine learning research conducted at UW-Madison
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
MABViT2 - Model Agnostic Bayesian Vision Transformer
Novel architecture for vision transformer with uncertainty quantification
MABViT2 - Model Agnostic Bayesian Vision Transformer
Novel architecture for vision transformer with uncertainty quantification
Project Overview:
Vision Transformers (ViTs) have emerged as powerful models for computer vision tasks but often lack reliable uncertainty quantification. This project addresses this gap by developing MABViT2, a Model Agnostic Bayesian Vision Transformer, enabling uncertainty estimation without architectural modifications.
Key Contributions:
- Developed a Bayesian ViT model that quantifies uncertainty without architectural changes
- Implemented a variational inference approach for parameter estimation
- Validated performance on benchmark datasets while maintaining competitive accuracy
- Demonstrated superior out-of-distribution detection compared to deterministic baselines
- Created a flexible implementation that can be applied to any existing Vision Transformer
Technical Details:
The MABViT2 framework uses a Monte Carlo Dropout method in the self-attention mechanism to approximate Bayesian inference. By running multiple forward passes with different dropout masks, the model generates a distribution of predictions that capture epistemic uncertainty. The implementation is compatible with existing ViT architectures like DeiT and ViT-B models.
Significance:
This work bridges a critical gap in computer vision by enabling uncertainty quantification in transformer-based models, which is essential for high-stakes applications like medical imaging and autonomous driving. The model-agnostic approach makes it straightforward to apply to existing systems without architectural redesign.
Vision-Language Navigation with Transformer Architectures
Transformer-based agent for navigating complex environments using natural language instructions
Vision-Language Navigation with Transformer Architectures
Transformer-based agent for navigating complex environments using natural language instructions
Project Overview:
This project addresses the challenge of vision-language navigation (VLN), where an agent must navigate to a target location following natural language instructions. The approach uses a transformer-based architecture to integrate visual, linguistic, and spatial information, enabling robust navigation in complex, previously unseen environments.
Key Contributions:
- Developed a multi-modal transformer architecture that jointly processes visual and linguistic inputs
- Implemented a hierarchical planning module that breaks down navigation into macro and micro actions
- Created a novel attention mechanism that grounds language instructions to visual features
- Designed a pre-training strategy using a combination of web-scale image-text pairs and navigation data
- Evaluated the approach on standard VLN benchmarks including R2R, REVERIE, and SOON datasets
Technical Implementation:
The core architecture consists of:
-
Visual Encoder: A vision transformer processes panoramic images at each viewpoint, extracting features at multiple scales.
-
Language Understanding Module: A language transformer encodes instructions and maintains an attention-based progress monitor.
-
Cross-Modal Reasoning: A fusion transformer integrates visual and linguistic features, generating a representation that guides navigation decisions.
-
Action Predictor: A hierarchical decision module that first selects high-level directions and then refines to specific viewpoints.
The model was implemented in PyTorch and trained using a combination of imitation learning and reinforcement learning, with a curriculum that gradually increased the complexity of navigation scenarios.
Results:
- 15% improvement in success rate on the R2R benchmark compared to previous methods
- 12% higher success rate on the REVERIE dataset for object-grounded navigation
- Effective zero-shot transfer to unseen environments
- Robust performance with ambiguous and complex language instructions
The project demonstrates the effectiveness of transformer architectures for embodied AI tasks, particularly those requiring multi-modal reasoning and long-horizon planning.
Robot Action Exploration using Bayesian Optimization
Novel reinforcement learning approach for efficient robot skill acquisition
Robot Action Exploration using Bayesian Optimization
Novel reinforcement learning approach for efficient robot skill acquisition
Project Overview:
This project addresses the challenge of efficient exploration in robotic manipulation tasks. Traditional reinforcement learning approaches often struggle with the high-dimensional action spaces and sparse rewards common in manipulation tasks. Our approach uses Bayesian optimization to guide exploration in a hierarchical action space, significantly improving learning efficiency.
Key Contributions:
- Developed a hierarchical exploration strategy that decomposes complex manipulation tasks into subtasks
- Implemented a Gaussian Process-based Bayesian optimization framework for efficient action selection
- Created a directed exploration mechanism based on information gain and expected improvement
- Designed a task-agnostic representation that generalizes across different manipulation scenarios
- Evaluated the approach on a range of real-world robotic manipulation tasks
Technical Implementation:
The framework consists of three main components:
-
Hierarchical Action Space: Complex manipulation tasks are represented as sequences of primitive actions organized in a hierarchical structure.
-
Bayesian Optimization: A Gaussian Process model maintains a belief over the reward function, guiding exploration toward promising regions of the action space.
-
Information-Directed Sampling: Actions are selected based on a combination of expected reward and information gain, balancing exploration and exploitation.
The system was implemented using PyTorch for the learning components and integrated with ROS for robot control. Experiments were conducted on a 7-DOF robotic arm performing various manipulation tasks.
Results:
- 45% faster skill acquisition compared to standard reinforcement learning approaches
- Successful learning of complex manipulation tasks with as few as 50 physical trials
- Effective transfer learning between related tasks
- Robust performance under varying initial conditions and object properties
The approach demonstrates significant potential for enabling robots to autonomously learn manipulation skills with minimal human supervision, a critical capability for deploying robots in unstructured environments.
Reinforcement Learning for Hexapod Robot
Applying reinforcement learning algorithms to optimize the locomotion of a six-legged robot
Reinforcement Learning for Hexapod Robot
Applying reinforcement learning algorithms to optimize the locomotion of a six-legged robot
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
NVIDIA
CUDA-Optimized Sparse Matrix Operations
High-performance matrix operations for ML applications running on NVIDIA GPUs
CUDA-Optimized Sparse Matrix Operations
High-performance matrix operations for ML applications running on NVIDIA GPUs
Project Overview:
This project addresses the computational bottlenecks in deep learning inference by developing optimized CUDA kernels for sparse matrix operations. While GPUs excel at dense computations, many modern neural networks benefit from sparsity, making specialized sparse kernels critical for performance.
Key Contributions:
- Developed custom CUDA kernels for sparse matrix-vector multiplication with format-specific optimizations
- Implemented block-sparse operations tailored for transformer attention mechanisms
- Created a pruning-aware convolution operator that dynamically adapts to various sparsity patterns
- Designed memory-efficient sparse matrix storage formats optimized for GPU memory access patterns
- Integrated the optimized kernels with popular deep learning frameworks like PyTorch and TensorFlow
Technical Details:
The implementation leverages advanced CUDA features including shared memory optimization, warp-level primitives, and thread coarsening to maximize throughput. The kernels support various sparsity patterns (structured, unstructured, and block sparsity) with format-specific optimizations.
For transformer models, specialized attention mechanism kernels were developed that exploit the inherent sparsity in attention masks. The convolution operators use pruning awareness to dynamically skip computations for zero weights, significantly improving inference speed.
Performance Results:
- 3.8x speedup for sparse matrix-vector multiplication compared to cuSPARSE
- 2.5x faster inference for transformer models with 80% sparsity
- 65% reduction in memory footprint for large language models
- Linear scaling across multiple GPU configurations
These optimizations enable significant speedups for inference workloads while maintaining model accuracy, making deployment of large-scale models more cost-effective.
GPU-Accelerated Physical Simulation Framework
Parallel physics simulation platform for robotics and graphics applications
GPU-Accelerated Physical Simulation Framework
Parallel physics simulation platform for robotics and graphics applications
Project Overview:
This project addresses the challenge of performing physically accurate simulations of complex environments in real-time. By leveraging GPU acceleration through CUDA, the framework achieves significant performance improvements while maintaining simulation accuracy, enabling applications in robotics, computer graphics, and VR/AR.
Key Features:
- Unified constraint-based physical simulation supporting rigid bodies, soft bodies, and fluids
- Highly parallel implementation of collision detection and constraint solving
- Spatial data structures optimized for GPU execution patterns
- Stable numerical integration methods suitable for interactive applications
- API compatibility with common robotics and graphics frameworks
Technical Implementation:
The core of the framework consists of a parallel constraint solver that processes thousands of constraints simultaneously on the GPU. For collision detection, a hierarchical spatial subdivision approach is used to efficiently cull non-colliding pairs of objects. Both broad-phase and narrow-phase collision detection are implemented as parallel algorithms.
The framework uses a position-based dynamics approach for soft body simulation, allowing for stable and efficient simulation of deformable objects. Fluid simulation is implemented using a smooth particle hydrodynamics (SPH) method, with neighbor finding accelerated through GPU-optimized spatial hashing.
Performance Results:
- 50-100x speedup over equivalent CPU implementations for rigid body simulation
- Real-time performance with up to 100,000 rigid bodies or 1 million particles
- Stable simulation at large time steps, suitable for interactive applications
- Efficient scaling across different NVIDIA GPU architectures
Applications:
The framework has been successfully applied to robotic simulation for reinforcement learning, real-time physics for game engines, and interactive visualization for scientific applications. Its performance characteristics make it particularly suitable for applications requiring both accuracy and interactivity, such as virtual prototyping and realistic VR environments.
DCT and IDCT Hardware Accelerator
Hardware implementation of Discrete Cosine Transform (DCT) and its inverse for signal processing ...
DCT and IDCT Hardware Accelerator
Hardware implementation of Discrete Cosine Transform (DCT) and its inverse for signal processing applications
This project implements a hardware accelerator for Discrete Cosine Transform (DCT) and Inverse Discrete Cosine Transform (IDCT) for signal processing and media applications.
Project Overview:
The core of this work is to implement a hardware accelerator for DCT and IDCT, which are crucial in various signal processing and media applications. With the growth of information technology, the need for efficient compression algorithms has become paramount. DCT has been widely used for several decades due to its incredible energy compaction properties. This project focuses on implementing hardware-level DCT and IDCT transforms for energy-efficient encoding and decoding. The implementation is done using Bluespec, a high-level hardware description language.
Key Features:
- Implementation of Fast DCT algorithm
- Implementation of IDCT algorithm
- Modular design for 4-point, 8-point, 16-point, and 32-point transforms
- Use of Butterfly and Hadamard modules for efficient computation
- Pipelined architecture for higher throughput
- The project demonstrates the potential for hardware acceleration in signal processing tasks, particularly in the context of media compression and decompression. It provides a foundation for further optimization and integration into larger systems dealing with video and image processing.
Hardware-Accelerated Computer Vision Library
Optimized vision algorithms for embedded systems and edge devices
Hardware-Accelerated Computer Vision Library
Optimized vision algorithms for embedded systems and edge devices
Project Overview:
This project addresses the challenge of deploying computer vision applications on resource-constrained embedded systems and edge devices. By developing hardware-optimized implementations of common vision algorithms and providing a consistent API across different platforms, the library enables efficient vision processing on a wide range of devices.
Key Features:
- Optimized implementations of fundamental vision operations (filtering, feature extraction, optical flow, etc.)
- Neural network acceleration for deep learning-based vision tasks
- Hardware-specific optimizations for various platforms (NVIDIA Jetson, Arm processors, DSPs)
- Automatic selection of optimal implementation based on available hardware
- Common API across all supported platforms for code portability
- Comprehensive performance profiling and power monitoring tools
- Support for both C++ and Python with minimal dependencies
Technical Implementation:
The library is structured as a layered architecture:
-
Core API Layer: Provides a consistent interface for all vision operations, abstracting hardware details from the user.
-
Algorithm Layer: Implements various vision algorithms with optimizations for numerical stability and accuracy on embedded platforms.
- Acceleration Layer: Contains hardware-specific implementations leveraging various acceleration technologies:
- CUDA for NVIDIA GPUs
- OpenCL for cross-platform GPU acceleration
- NEON/SVE optimizations for Arm CPUs
- DSP offloading for supported SoCs
- Neural accelerator integration (NVDLA, NPU, etc.)
- Platform Layer: Handles device detection, capability querying, and optimal implementation selection.
Performance Results:
- 5-20x speedup compared to general-purpose CPU implementations
- 3-8x power efficiency improvement for common vision pipelines
- Real-time performance for many vision tasks on embedded platforms:
- 60+ FPS for 1080p image filtering on Jetson Nano
- 30+ FPS for feature detection and tracking on Arm Cortex-A devices
- 15+ FPS for basic neural network inference on low-power microcontrollers
Applications:
The library has been successfully applied to various edge computing applications:
- Smart camera systems for retail analytics
- Autonomous robot navigation
- Augmented reality on mobile devices
- Industrial quality control systems
- Smart city infrastructure
- Low-power IoT vision sensors
The project enables developers to leverage computer vision capabilities on constrained devices without requiring expertise in hardware-specific optimization, accelerating the deployment of intelligent edge applications.
Natural Language Processing for Clinical Data
Using NLP techniques to extract insights from medical records
Natural Language Processing for Clinical Data
Using NLP techniques to extract insights from medical records
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
IIT Madras
Cheetah Soft Robotics Simulator
Simulation platform for soft robots with real-time performance using GPU acceleration
Cheetah Soft Robotics Simulator
Simulation platform for soft robots with real-time performance using GPU acceleration
Project Overview:
This project addresses the challenge of efficiently simulating soft and hybrid rigid-soft robots for design and control applications. Inspired by biological systems like cheetahs, which use their flexible spine for enhanced locomotion, the simulator enables exploration of bio-inspired designs that incorporate soft, deformable components alongside traditional rigid elements.
Key Features:
- FEM-based deformation model for accurate simulation of soft materials with varying properties
- GPU-accelerated parallel solver achieving real-time performance for complex models
- Unified treatment of rigid and soft body dynamics within a single simulation framework
- Contact model specifically designed for soft-rigid interactions
- Open-source implementation with Python and C++ APIs
Technical Implementation:
The core of the simulator is built on a finite element method (FEM) approach using a corotational formulation for large deformations. To achieve real-time performance, the computational bottleneck of solving large sparse linear systems is addressed through a custom GPU-accelerated preconditioned conjugate gradient solver.
The system incorporates a unified constraint-based formulation that handles both soft body deformation and rigid body dynamics, allowing for seamless simulation of hybrid systems. A specialized contact model accounts for the unique challenges of soft material contact, including friction and self-collision.
Applications:
The simulator has been applied to several bio-inspired robotic designs, including:
-
Cheetah-inspired robot: A quadrupedal robot with a flexible spine, demonstrating how controlled spinal flexibility can enhance running efficiency and maneuverability.
-
Soft grippers: Simulation of pneumatically actuated soft grippers for delicate object manipulation.
-
Tensegrity robots: Robots that use a combination of rigid struts and flexible tensile elements for locomotion and adaptation.
Impact:
The simulator enables researchers to explore the design space of soft and hybrid robots more efficiently, testing concepts virtually before physical prototyping. The ability to run simulations in real-time facilitates the development of control algorithms and the application of learning-based approaches to this challenging domain.
Carry Save Multiplier Design
Implementation of an 8x8 carry save multiplier with optimized CMOS design techniques
Carry Save Multiplier Design
Implementation of an 8x8 carry save multiplier with optimized CMOS design techniques
Timelapse of 8-bit CSM
Designed and implemented a compact 8x8 carry save multiplier, leveraging CMOS technology for digital blocks like Inverters, NAND gates, and Full adders, ensuring efficient operation and verification.
Custom Compiler for MuJoCo Physics Engine
Specialized compiler for accelerating physics-based simulation on heterogeneous hardware
Custom Compiler for MuJoCo Physics Engine
Specialized compiler for accelerating physics-based simulation on heterogeneous hardware
Project Overview:
This project addresses the computational bottleneck in physics-based simulation for reinforcement learning and robotics applications. By developing a specialized compiler for MuJoCo physics engine computations, the system achieves significant performance improvements while maintaining simulation accuracy and enabling gradient-based optimization through automatic differentiation.
Key Contributions:
- Developed a domain-specific compiler for MuJoCo physics that performs optimizations specific to dynamics simulation
- Implemented automatic differentiation for the entire simulation pipeline, enabling gradient-based optimization
- Created a code generator targeting both CPU (with SIMD vectorization) and GPU (CUDA) backends
- Designed a memory layout optimizer that improves cache locality and reduces memory transfers
- Integrated the compiler with popular reinforcement learning frameworks like PyTorch and JAX
Technical Implementation:
The compiler pipeline consists of several stages:
-
Intermediate Representation: Physics computations are represented in a domain-specific IR that captures the mathematical structure of dynamics problems.
-
Analysis and Optimization: The compiler performs graph-based analyses to identify parallelizable computations, redundant calculations, and opportunities for memory optimization.
-
Automatic Differentiation: The entire simulation pipeline is made differentiable through source code transformation, enabling efficient computation of gradients.
-
Backend Code Generation: Optimized code is generated for multiple targets including multicore CPUs with SIMD extensions and NVIDIA GPUs via CUDA.
The system supports the full MuJoCo feature set while providing a clean Python API that integrates with machine learning frameworks.
Performance Results:
- 10x average speedup for forward dynamics simulation compared to standard MuJoCo
- 15x faster gradient computation compared to finite-difference methods
- 8x acceleration of reinforcement learning training loops on benchmark tasks
- Efficient scaling from desktop computers to HPC clusters
Applications:
The compiler has been successfully applied to accelerate reinforcement learning for robotic control, trajectory optimization for legged locomotion, and high-throughput evolutionary algorithms for robot design. The ability to efficiently compute gradients through physics simulations enables new approaches to controller design and system identification problems.
Autonomous Hexapod Robot
Designed and built a six-legged robot with advanced locomotion capabilities
Autonomous Hexapod Robot
Designed and built a six-legged robot with advanced locomotion capabilities
Project Overview:
This project involved designing and constructing a six-legged robot (hexapod) with autonomous capabilities. The hexapod features a distributed control system architecture where each leg has independent control while a central controller coordinates overall movement patterns and stability.
Key Features:
- Six-legged design with 3 degrees of freedom per leg (18 actuated joints total)
- Custom-designed PCBs for motor control and power distribution
- Implemented advanced gait generation algorithms for different terrain types
- Developed a real-time stability management system using accelerometer and gyroscope data
- Integrated computer vision for obstacle detection and navigation planning
- Designed a lightweight but durable chassis using 3D-printed components
Technical Implementation:
The robot uses a hierarchical control system with an ARM Cortex-M4 microcontroller as the main controller and dedicated controllers for each leg. Communication between controllers happens over a custom real-time protocol. The gait generator implements several locomotion patterns including tripod, wave, and ripple gaits that can be switched dynamically based on terrain.
A RaspberryPi handles higher-level functions including computer vision through a Pi Camera module, processing images to detect obstacles and plan navigation paths. The power system features lithium polymer batteries with efficient DC-DC conversion to maximize runtime.
Applications:
The hexapod platform demonstrates capabilities relevant to search and rescue operations, exploration of hazardous environments, and as an educational platform for robotics research. Its ability to navigate uneven terrain makes it suitable for applications where wheeled robots would struggle.
Autonomous UAV Navigation System
Vision-based navigation system for drones operating in GPS-denied environments
Autonomous UAV Navigation System
Vision-based navigation system for drones operating in GPS-denied environments
Project Overview:
This project addresses the challenge of enabling autonomous UAV operation in environments where GPS signals are unavailable or unreliable. By relying solely on onboard sensing and computing, the system provides robust navigation capabilities for applications including search and rescue, infrastructure inspection, and indoor operations.
Key Features:
- Visual-inertial odometry for accurate state estimation without GPS
- Real-time 3D mapping and simultaneous localization (SLAM)
- Learning-based obstacle detection and avoidance
- Path planning with dynamic obstacle handling
- Fault-tolerant control system with emergency recovery modes
- Lightweight implementation suitable for deployment on commercial drones
- Development of a custom simulation environment for testing and validation
Technical Implementation:
The system consists of four main components:
-
Perception: A visual-inertial odometry pipeline fuses data from stereo cameras and an IMU to estimate the drone’s position and orientation. This is complemented by a lightweight SLAM system that builds and maintains a 3D map of the environment.
-
Obstacle Avoidance: A deep learning-based approach detects obstacles from camera images, while a secondary system uses depth information for obstacle verification. The combined system provides reliable obstacle detection even in challenging lighting conditions.
-
Planning: A hierarchical planning system combines global path planning using a topological map with local trajectory optimization that accounts for dynamics constraints and obstacle avoidance.
-
Control: A robust control system translates planned trajectories into motor commands, with adaptive gains to handle different flight conditions and failure modes.
The entire system runs on an NVIDIA Jetson Xavier NX onboard computer, with a custom software stack developed using ROS and optimized for real-time performance.
Applications and Results:
The system has been successfully deployed in several applications:
- Search and Rescue: Autonomous exploration of disaster sites with detection of victims using thermal imaging
- Infrastructure Inspection: Automated inspection of bridges and buildings with detailed 3D reconstruction
- Warehouse Inventory: Indoor navigation for inventory tracking and management
Performance metrics demonstrate:
- Localization accuracy of ±5cm in controlled environments
- Obstacle detection range of up to 10m with 95% accuracy
- Successful navigation through complex environments with doorways and corridors
- Flight endurance of 15 minutes with full autonomy stack active
Computer Vision for Autonomous Systems
Developing robust vision systems for self-driving vehicles
Computer Vision for Autonomous Systems
Developing robust vision systems for self-driving vehicles
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
AI-Powered GTA V Mod for Autonomous Driving Research
Open-source platform for reinforcement learning and computer vision in simulated urban environments
AI-Powered GTA V Mod for Autonomous Driving Research
Open-source platform for reinforcement learning and computer vision in simulated urban environments
Project Overview:
This project addresses the challenge of developing and testing autonomous driving systems by creating a high-fidelity simulation environment based on Grand Theft Auto V. By leveraging the game’s photorealistic graphics, complex physics, and diverse urban environments, the platform enables research on perception, decision-making, and control algorithms for autonomous vehicles.
Key Features:
- Realistic sensor simulation including cameras, LiDAR, radar, and ultrasonic sensors
- Full access to ground truth data including semantic segmentation, depth maps, and object positions
- Programmable traffic scenarios with customizable vehicle behaviors
- Weather and lighting condition control for testing robustness
- Python API for integration with popular machine learning frameworks
- Data collection pipeline for creating training datasets
- Benchmarking suite for comparing different autonomous driving approaches
Technical Implementation:
The system consists of three main components:
-
Game Integration: A native plugin that interfaces with the game engine to extract rendering information, control vehicles, and modify the game environment.
-
Sensor Simulation: A physics-based simulation layer that generates realistic sensor outputs based on the game state, including camera images with proper distortion, LiDAR point clouds with appropriate noise characteristics, and radar returns.
-
Research Interface: A Python API that provides access to simulation controls, sensor data, and ground truth information, with built-in support for reinforcement learning environments and computer vision datasets.
The modification was implemented using a combination of C++ for the game integration and Python for the research interface, with optimized data transfer between the two.
Applications:
The platform has been used for various autonomous driving research applications:
- Training and evaluating perception algorithms in diverse and challenging conditions
- Developing reinforcement learning agents for urban driving scenarios
- Benchmarking decision-making algorithms for complex traffic situations
- Generating synthetic training data for machine learning models
- Testing edge cases and rare events that are difficult to encounter in real-world testing
Impact:
By providing an accessible, high-fidelity simulation environment, this project helps accelerate autonomous driving research without the high costs and safety concerns associated with real-world testing. The open-source nature of the platform has enabled researchers from various institutions to contribute and build upon the framework.
Early AI Research Project
Early exploration of neural networks for pattern recognition
Early AI Research Project
Early exploration of neural networks for pattern recognition
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
High School
High School Project
Project from pre-college years
High School Project
Project from pre-college years
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images, even citations (missing reference). Say you wanted to write a bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>
Robotics Competition Project
Award-winning high school robotics project
Robotics Competition Project
Award-winning high school robotics project
Every project has a beautiful feature showcase page. It’s easy to include images in a flexible 3-column grid format. Make your photos 1/3, 2/3, or full width.
To give your project a background in the portfolio page, just add the img tag to the front matter like so:
---
layout: page
title: project
description: a project with a background image
img: /assets/img/12.jpg
---
You can also put regular text between your rows of images. Say you wanted to write a little bit about your project before you posted the rest of the images. You describe how you toiled, sweated, bled for your project, and then… you reveal its glory in the next row of images.
The code is simple. Just wrap your images with <div class="col-sm"> and place them inside <div class="row"> (read more about the Bootstrap Grid system). To make images responsive, add img-fluid class to each; for rounded corners and shadows use rounded and z-depth-1 classes. Here’s the code for the last row of images above:
<div class="row justify-content-sm-center">
<div class="col-sm-8 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
<div class="col-sm-4 mt-3 mt-md-0">
{% include figure.liquid path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
</div>
</div>